Data layers and transforms
Overview
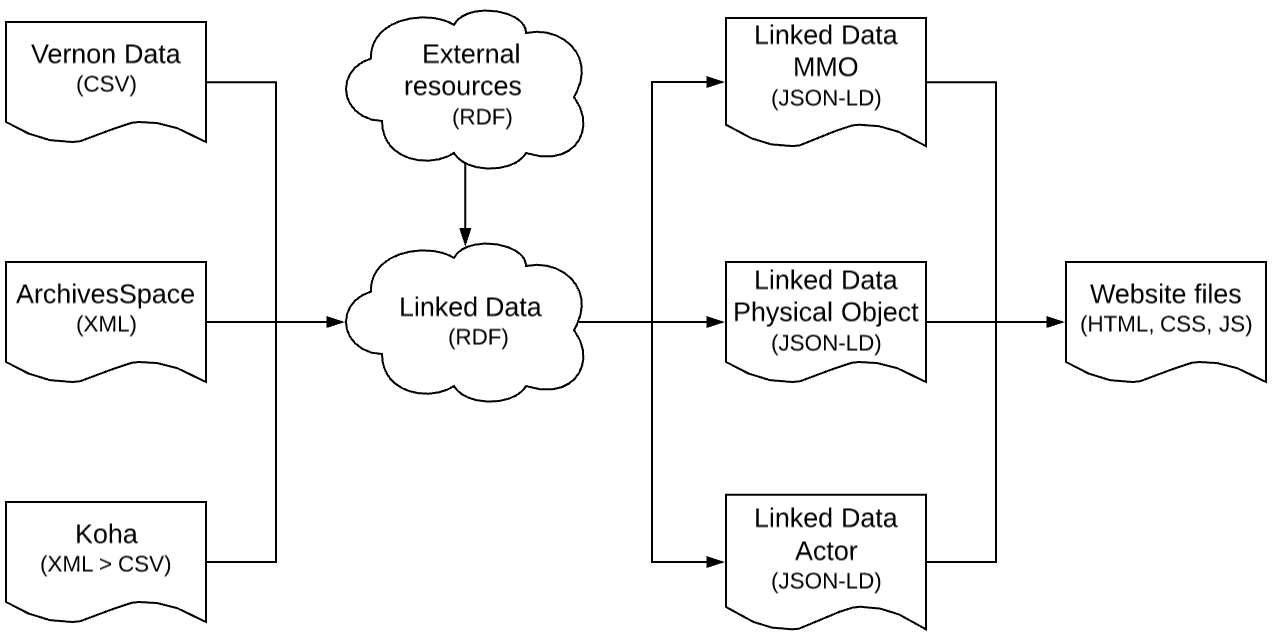
Data flows through three layers on its way to becoming front-end pages: tabular, linked data as statements, and linked data as documents.
Tabular data and source data
The first of these data layers is simply the data as we get it from a source system. In the case of museum collections data, this data usually arrives at the pipeline as CSV exports or a JSON API. For archival materials we ingest EAD3/XML documents and for library materials we ingest MARCXML.
Fetchable data sources
There are not currently "fetchable" data sources (APIs that can be accessed directly by scripts). There would be individual pipeline commands for each of these, and the contents of the fetch would be deposited into the data/ directory of the data pipeline and treated from that point forward like any other data source.
Prepartion of transformation
In some of these cases source data needs special handling--branch selection of archival hierarchies, escaping embedded HTML, etc. If these are needed the pipeline generates an intermediate representation that is then passed to the linked data transforms.
Transformation
Every data source is passed through a linked data transform:
- Complex data sources use Karma, a tool written by USC's Information Sciences Institute to handle authoring and execution of linked data transformations. If a source data structure has nested entities, is in XML, or will produce a complex output then we use Karma.
- Simply structured data (usually reconciliation and relationships data) uses a CSV-W metadata manifest and transform
- For RDF data we do nothing and simply ingest the RDF directly
At the end of the transformation process, linked data is loaded into the triplestore. More details on transformations can be found in the collections app repository.
Augmentation and querying
At this stage we begin enhancing the graph we've loaded into the database. We:
- Align all the classifications and people with their reconciliations
- Run queries to count the number of archival components contained in a given archival hierarchy branch
- Fetch recent labels for AAT terms
Composition into documents
Then we take the graph full of triples, query via SPARQL construct queries for entities and their underlying properties, and frame the results so that we have JSON-LD documents that show us objects with their identifiers, descriptive cataloguing, participants, etc.
At this stage we also create a data release with a versioned tag that indicates the date it was produced.
Simplification and page building
Finally, we take the JSON-LD documents and produce simplified versions that the page builder uses to produce HTML documents for the site, and by the search index for the browse and search pages.
References
- TBD